 Синтаксический анализ файлов
Синтаксический анализ файлов .docx может быть полезен во многих приложениях, таких как анализ текста, извлечение данных и преобразование документов. В этой статье будет рассмотрено решение для синтаксического анализа файлов .docx с использованием языка программирования Rust.
Решение представляет собой простое приложение командной строки, которое принимает имя файла в качестве входных данных и выводит текстовое содержимое документа на консоль.
Для достижения этой цели мы будем использовать набор библиотек и зависимостей, включая clap для анализа аргументов командной строки, docx-rs для анализа файла .docx, serde_json для преобразования проанализированных данных в объект JSON, std для операций ввода-вывода файлов и anyhow.
Вот блок-схема, показывающая общий процесс:
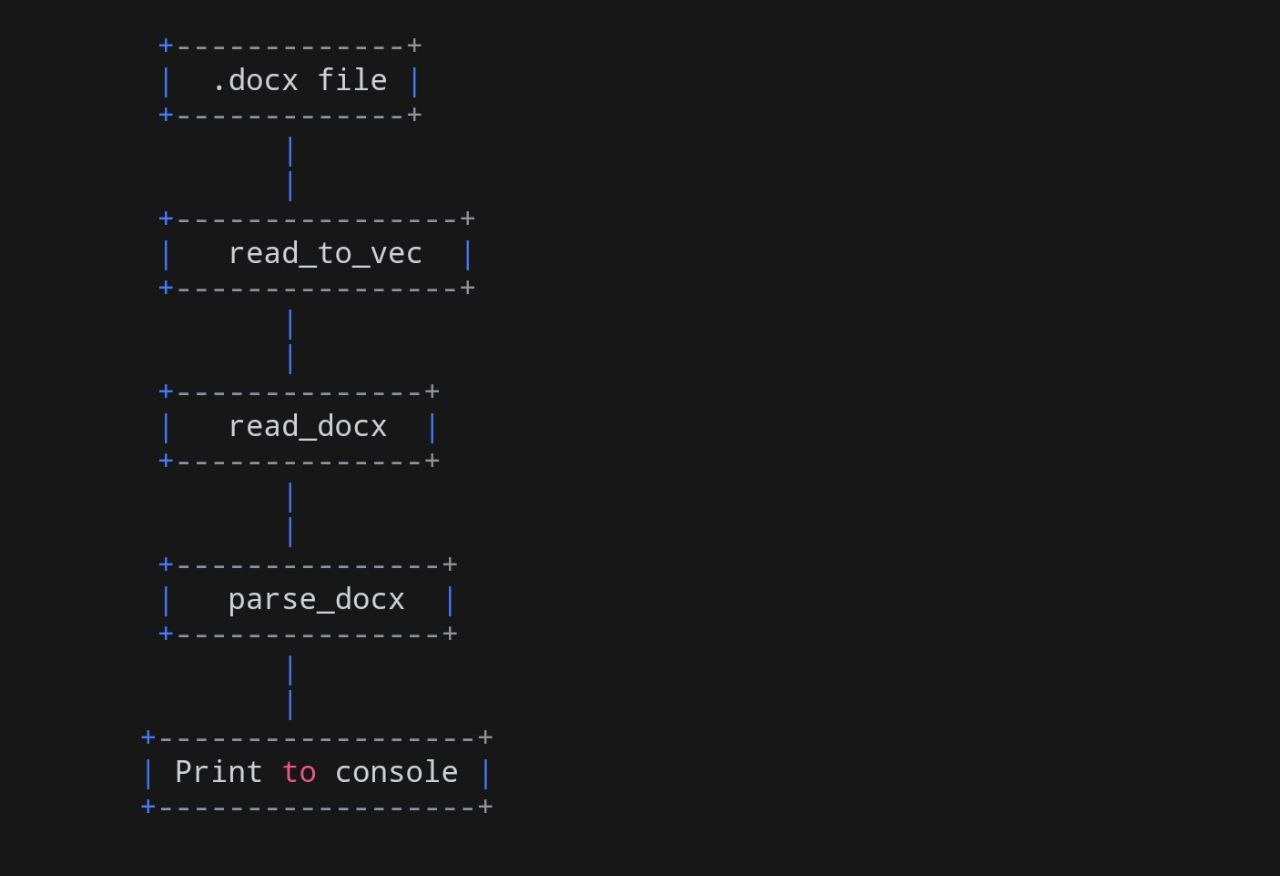
Теперь, когда у нас есть обзор решения, давайте углубимся в библиотеки и зависимости, которые мы будем использовать в этом коде.
Установка
Прежде чем мы сможем начать, мы должны убедиться, что установлены необходимые библиотеки. В любом случае, мы будем использовать clap, docx_rs, serde_json, anyhow и стандартную библиотеку Rust. Вы можете добавить их к своему Cargo.toml:
[dependencies]
anyhow = "1.0.68"
clap = "2.33.0"
docx_rs = "0.1.1"
serde_json = "1.0.58"Разбор файла .docx
Первым шагом при разборе файла .docx является считывание его содержимого в вектор байтов. Для выполнения этой задачи мы можем использовать модули std::fs::File и std::io::Read из стандартной библиотеки Rust.
Вот функция read_to_vec, которая принимает имя файла и считывает его содержимое в Vec<u8>:
fn read_to_vec(file_name: &str) -> anyhow::Result<Vec<u8>> {
let mut buf = Vec::new();
std::fs::File::open(file_name)?.read_to_end(&mut buf)?;
Ok(buf)
}Как только у нас будет содержимое файла .docx в виде вектора байт, мы можем передать его функции read_docx, предоставляемой библиотекой docx_rs. Эта функция проанализирует содержимое файла .docx и вернет структуру Docx, которая содержит текстовое содержимое файла в формате JSON.
Вот функция parse_docx, которая принимает имя файла в качестве аргумента и анализирует файл docx с помощью docx_rs и возвращает значение JSON файла docx
fn parse_docx(file_name: &str) -> anyhow::Result<()> {
let data: Value = serde_json::from_str(&read_docx(&read_to_vec(file_name)?)?.json())?;
if let Some(children) = data["document"]["children"].as_array() {
children.iter().for_each(read_children);
}
Ok(())
}Извлечение текстового содержимого
Как только у нас будет значение JSON файла .docx, мы сможем использовать библиотеку serde_json для извлечения текстового содержимого. Значение JSON содержит вложенную структуру элементов, поэтому нам нужно пройти по дереву и рекурсивно искать текстовые элементы. Мы можем использовать структуру Value, предоставляемую библиотекой serde_json, для представления значения JSON.
Вот функция read_children, которая принимает узел и проверяет, есть ли у него ключ ‘children’ и тип массива, затем она выполняет итерацию по дочерним элементам и вызывает функцию read_children, если тип дочернего элемента не “text”. В противном случае он печатает текстовое содержимое дочернего элемента.
fn read_children(node: &Value) {
if let Some(children) = node["data"]["children"].as_array() {
children.iter().for_each(|child| {
if child["type"] != "text" {
read_children(child);
} else {
println!("{}", child["data"]["text"]);
}
});
}
}Собирая все это воедино
Теперь мы можем собрать все части воедино в основной функции. Сначала мы анализируем аргументы командной строки, используя функцию Args::parse(), предоставляемую библиотекой clap. Затем мы вызываем функцию parse_docx с именем файла, подлежащего анализу, которая, в свою очередь, вызывает функции read_to_vec, read_docx и read_children. Наконец, основная функция возвращает Ok(()).
fn main() -> anyhow::Result<()> {
let args = Args::parse();
parse_docx(&args.name)?;
Ok(())
}Полный код выглядит следующим образом:
use clap::Parser;
use docx_rs::*;
use serde_json::Value;
use std::io::Read;
#[derive(Parser, Debug)]
#[command(author, version, about, long_about = None)]
struct Args {
#[arg(short, long)]
name: String,
}
fn parse_docx(file_name: &str) -> anyhow::Result<()> {
let data: Value = serde_json::from_str(&read_docx(&read_to_vec(file_name)?)?.json())?;
if let Some(children) = data["document"]["children"].as_array() {
children.iter().for_each(read_children);
}
Ok(())
}
fn read_children(node: &Value) {
if let Some(children) = node["data"]["children"].as_array() {
children.iter().for_each(|child| {
if child["type"] != "text" {
read_children(child);
} else {
println!("{}", child["data"]["text"]);
}
});
}
}
fn read_to_vec(file_name: &str) -> anyhow::Result<Vec<u8>> {
let mut buf = Vec::new();
std::fs::File::open(file_name)?.read_to_end(&mut buf)?;
Ok(buf)
}
fn main() -> anyhow::Result<()> {
let args = Args::parse();
parse_docx(&args.name)?;
Ok(())
}В финале
В этой статье я продемонстрировал, как использовать язык программирования Rust для синтаксического анализа содержимого файла .docx и извлечения его текстового содержимого. Для выполнения этой задачи использовал библиотеки docx_rs и serde_json.
Это базовый пример того, как анализировать файлы .docx с помощью Rust. Понимание формата docx и представления в формате JSON может обеспечить более сложные функциональные возможности. Это может быть использовано для извлечения информации из многих файлов docx или для автоматизации процесса извлечения текста.