 В предыдущих историях мы написали структуру данных хеш-таблицы полностью с нуля в Rust. Сегодня давайте напишем тестовую функцию, чтобы убедиться, что наша хеш-таблица ведет себя точно так же, как и стандартная библиотека. Затем мы напишем простые тесты для сравнения их производительности.
В предыдущих историях мы написали структуру данных хеш-таблицы полностью с нуля в Rust. Сегодня давайте напишем тестовую функцию, чтобы убедиться, что наша хеш-таблица ведет себя точно так же, как и стандартная библиотека. Затем мы напишем простые тесты для сравнения их производительности.
Что касается теста, я вызову пять методов insert(), get(), get_mut(), remove() и len() миллион раз в случайном порядке со случайным ключом и значениями. Для каждой итерации я сравниваю результат, с результатом полученным от объекта, созданного от стандартной библиотеки. Этот тест проверяет, что обе реализации имеют одинаковое поведение.
use rand::distributions::*;
fn run_test() {
let mut map1 = rust_hashmap::HashMap::new(); // наша реализация
let mut map2 = std::collections::HashMap::new(); // стандартная реализация библиотеки
let key_gen = Uniform::from(0..1000); // случайный ключ, значение
let op_gen = Uniform::from(0..5); // выбор операции
let mut rng = rand::thread_rng();
for _ in 0..10000000 {
let val = key_gen.sample(&mut rng);
let key = val;
match op_gen.sample(&mut rng) {
0 => {
// insert
assert_eq!(map1.insert(key, val), map2.insert(key, val));
}
1 => {
// get mut
assert_eq!(
map1.get_mut(&key).map(|x| {
*x += 1;
x
}),
map2.get_mut(&key).map(|x| {
*x += 1;
x
})
);
}
2 => {
assert_eq!(map1.get(&key), map2.get(&key));
}
3 => {
assert_eq!(map1.remove(&key), map2.remove(&key));
}
_ => {
assert_eq!(map1.len(), map2.len());
}
}
}
}Я проводил тест несколько раз, и у тестов никогда не было сбоев. Далее необходимо измерить разницу в производительности между ними. Для этого я напишу MapTrait, который разделяет общий интерфейс между ними, чтобы я смог написать общую функцию эталонного теста.
fn run_bench_i64<M>()
where
M: MapTrait<i64, i64>,
{
let mut map = M::new();
let key_gen = Uniform::from(0..1000);
let op_gen = Uniform::from(0..4);
let mut rng = rand::thread_rng();
for _ in 0..10000000 {
let val = key_gen.sample(&mut rng);
let key = val;
match op_gen.sample(&mut rng) {
0 => {
// insert
map.insert(key, val);
}
1 => {
// get mut
map.get_mut(&key).map(|x| {
*x += 1;
x
});
}
2 => {
// get
map.get(&key);
}
3 => {
// remove
map.remove(&key);
}
_ => {}
}
}
}Аналогично тестовой функции, будем повторять случайную операцию со случайным ключом, и значением в данной хэш-таблице. Ниже показан бенчмарк выполнения этой функции для нашей пользовательской реализации по сравнению со стандартной библиотекой, скомпилированной с флагом оптимизации.
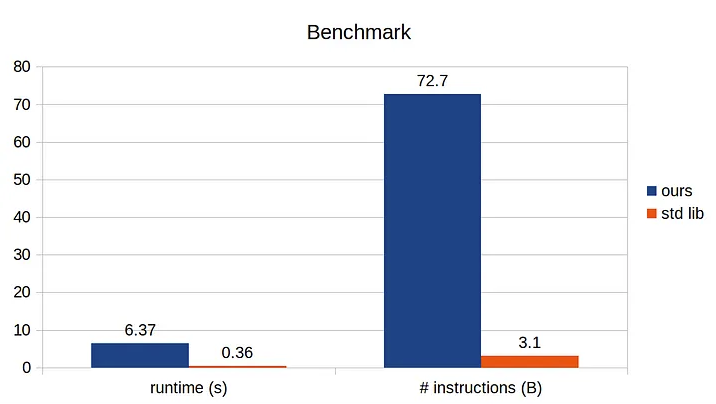
Разница огромна! Разница во времени выполнения и # instructions, необходимые для выполнения теста, различаются в 20 раз. Что происходит?
При тестировании программы мы должны учитывать еще одну метрику: потребление памяти.
Мы знаем, что наша хеш-таблица работает так, как ожидалось с точки зрения поведения, но мы не знаем, эффективно ли она использует системную память. Самый простой способ измерения потребления памяти программой - это запуск с временем gnu и проверка размера резидентного набора (RSS). Это может быть немного сложно, потому что на bash, например, время является встроенной командой. Для явного запуска времени gnu необходимо ввести полный путь:
$ which time
/usr/bin/time
$ /usr/bin/time -v ./a.out 2>&1 | grep "Maximum resident"
Maximum resident set size (kbytes): 39396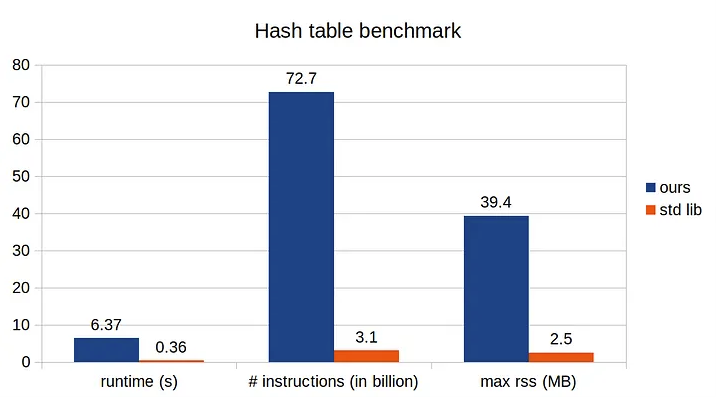
Хорошо, у нас есть идея. Наша реализация как-то очень неэффективно управляет памятью, что является основным узким местом производительности. Из за этого я чувствую, что мы должны посмотреть наш метод resize(), чтобы увидеть, что происходит. Действительно, виновником является то, что мы безоговорочно удваиваем размер массива, даже если занятые записи отсутствуют. Более подходящий подход заключается в изучении занятого места и принятии решения о сохранении размера массива или его удвоении.
--- before
+++ after
+
+ fn occupied_factor(&self) -> f64 {
+ if self.xs.is_empty() {
+ 1.0
+ } else {
+ self.n_occupied as f64 / self.xs.len() as f64
+ }
+ }
+
fn resize(&mut self) {
- let new_size = max(64, self.xs.len() * 2);
+ let resize_factor = if self.occupied_factor() > 0.75 { 2 } else { 1 };
+ let new_size = max(64, self.xs.len() * resize_factor);
let mut new_table = Self {
xs: (0..new_size).map(|_| Entry::Vacant).collect(),
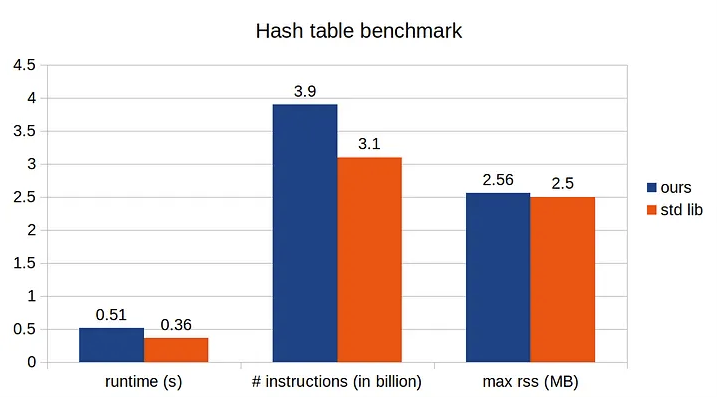
n_occupied: 0,С этим простым изменением наша реализация улучшилась более чем в 10 раз, и наша реализация вполне сравнима со стандартной библиотекой!
В следующей статье мы будем оптимизировать нашу реализацию еще дальше, так что будьте готовы!