Давайте возьмем стандартную библиотечную реализацию HashMap, измеренную на нашем синтетическом тесте. Для этого мы запустим профилировщик и изучим, где главное узкое место, и попытаемся улучшить это.
Для моей системы Linux я буду использовать утилиту perf. Не забудьте построить исполняемый файл с использованием символов отладки. Кроме того, рекомендуется профилировать релизную сборку.
$ perf record ./a.out
WARNING: Kernel address maps (/proc/{kallsyms,modules}) are restricted,
check /proc/sys/kernel/kptr_restrict and /proc/sys/kernel/perf_event_paranoid.
Samples in kernel functions may not be resolved if a suitable vmlinux
file is not found in the buildid cache or in the vmlinux path.
Samples in kernel modules won't be resolved at all.
If some relocation was applied (e.g. kexec) symbols may be misresolved
even with a suitable vmlinux or kallsyms file.
Couldn't record kernel reference relocation symbol
Symbol resolution may be skewed if relocation was used (e.g. kexec).
Check /proc/kallsyms permission or run as root.
[ perf record: Woken up 1 times to write data ]
[ perf record: Captured and wrote 0.057 MB perf.data (1467 samples) ]
$ perf report
Samples: 1K of event 'cycles', Event count (approx.): 1597855314
Overhead Command Shared Object Symbol
30.31% test test [.] rust_hashmap::hashmap::HashMap<Key,Val>::get_index
27.61% test test [.] test::main
10.65% test test [.] <rust_hashmap::hashmap::HashMap<K,V> as rust_hashmap::map::MapTrait<K,V>>::remove
10.18% test test [.] <rust_hashmap::hashmap::HashMap<K,V> as rust_hashmap::map::MapTrait<K,V>>::insert
7.63% test test [.] rand_chacha::guts::refill_wide::impl_avx2
7.62% test test [.] <core::hash::sip::Hasher<S> as core::hash::Hasher>::write
4.49% test test [.] rand::rng::Rng::gen
0.60% test test [.] rand_chacha::guts::refill_wideСогласно отчету профилировщика, наибольшие накладные расходы (30%) приходятся на метод get_index(). Для интереса, вот как реализуется метод:
fn get_index<Q>(&self, key: &Q) -> usize
where
Key: Borrow<Q>,
Q: Eq + Hash,
{
let mut hasher = DefaultHasher::new();
key.hash(&mut hasher);
hasher.finish() as usize % self.xs.len()
}Возможно, это - функция хеширования, которая занимает слишком много времени? Ну, давайте исследуем её далее, войдя в инструкции уровня ассемблера:
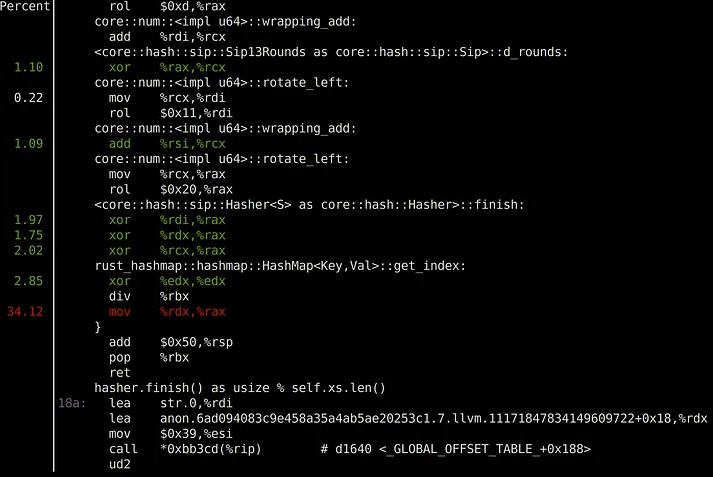
Обратите внимание, что наше узкое место появляется после метода hasher::finish() непосредственно перед возвратом get_index(). Наиболее важной операцией, по мнению профилировщика, является mov. Имеет ли это смысл? mov-операция, вероятно, является всего лишь одним циклом, поскольку она перемещает между регистрами.
Ну, на самом деле профилировщик не может указать на точную инструкцию. Скорее, это указывает на то что рядом. Обратите внимание на предыдущую инструкцию, которая является div. Это фактический виновник узкого места, что имеет смысл. Оператор деления будет использовать несколько циклов. Вопрос в том, откуда это взялось? Посмотрите на последнюю строку метода get_index():
hasher.finish() as usize % self.xs.len()Вот и все. Существует оператор деление по модулю %, который по существу является операцией деления и получает остаток. Это наше главное узкое место. Для каждого вызова get(), get_mut(), insert() или remove() необходимо искать индекс в массиве, поэтому имеет смысл вызывать этот метод миллионы раз. Операция div сама по себе составляет всего несколько циклов, но когда она выполняется неоднократно в течение миллиона раз, накладные расходы суммируются.
Мы можем что-нибудь с этим сделать? Мы не можем оптимизировать div в целом, но мы можем для некоторых особых случаев, например, когда делитель является степень 2. Напомним, что наш метод resize() удваивает массив, начиная с 64. Из этого мы знаем, что размер массива всегда будет равен 2. При этом операция по модулю идентична побитовому AND с array.len() - 1. Поразрядная операция и операция вычитания должны состоять из одного цикла. Давайте поищем все % операции и заменим нашей оптимизированной битовой операцией. Для этого я создам метод index(). Готов поспорить, что компилятор встроит метод, так что не беспокойтесь о затратах на вызов функции.
--- before
+++ after
@@ -42,13 +42,19 @@ pub struct HashMap<Key, Val> {
}
impl<Key: Eq + Hash, Val> HashMap<Key, Val> {
+ fn index(&self, hash: usize) -> usize {
+ hash & (self.xs.len() - 1)
+ }
+
fn shift_down(&mut self, idx: usize) {
- let next = (idx + 1) % self.xs.len();
+ let next = self.index(idx + 1);
match &mut self.xs[next] {
Entry::Occupied { psl, .. } if *psl > 0 => {
@@ -118,7 +132,7 @@ impl<Key: Eq + Hash, Val> HashMap<Key, Val> {
{
let mut hasher = DefaultHasher::new();
key.hash(&mut hasher);
- hasher.finish() as usize % self.xs.len()
+ self.index(hasher.finish() as usize)
}
pub fn new() -> Self {
@@ -163,7 +177,7 @@ impl<Key: Eq + Hash, Val> HashMap<Key, Val> {
}
}
}
- idx = (idx + 1) % self.xs.len();
+ idx = self.index(idx + 1);
cur_psl += 1;
}
}
@@ -221,7 +235,7 @@ impl<Key: Eq + Hash, Val> HashMap<Key, Val> {
}
}
- self.shift_down(idx % self.xs.len());
+ self.shift_down(self.index(idx));
result.map(|val| {
self.n_occupied -= 1;С этим изменением, давайте снова запустим профилировщик, чтобы увидеть, изменились показания или нет:
Samples: 1K of event 'cycles', Event count (approx.): 1456495885
Overhead Command Shared Object Symbol
28.79% test test [.] test::main
24.42% test test [.] rust_hashmap::hashmap::HashMap<Key,Val>::get_index
12.58% test test [.] <rust_hashmap::hashmap::HashMap<K,V> as rust_hashmap::map::MapTrait<K,V>>::insert
10.84% test test [.] <rust_hashmap::hashmap::HashMap<K,V> as rust_hashmap::map::MapTrait<K,V>>::remove
9.03% test test [.] rand_chacha::guts::refill_wide::impl_avx2
7.29% test test [.] <core::hash::sip::Hasher<S> as core::hash::Hasher>::write
5.90% test test [.] rand::rng::Rng::gen
0.87% test test [.] rand_chacha::guts::refill_wide
0.26% test ld-linux-x86-64.so.2 [.] dl_main
0.02% test [unknown] [k] 0xffffffff8710070a
0.00% perf-ex [unknown] [k] 0xffffffff872e12d2Действительно, накладные расходы get_index() сократились с 30% до 24%. Не резкое улучшение, но и неплохое для всего нескольких строк изменений кода. Давайте измерим время выполнения:
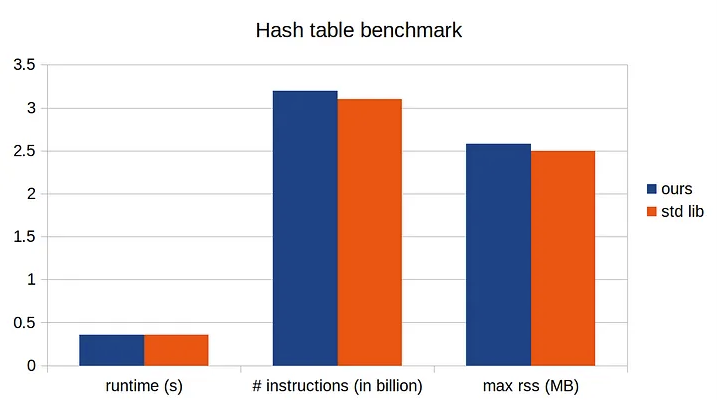
После оптимизации по модулю наша реализация работает наравне со стандартной библиотекой!